ABSTRACT
In recent years, the advancement of sensor technology has led to the generation of heterogeneous Internet-of-Things (IoT) data by smart cities. Thus, the development and deployment of various aspects of IoT-based applications are necessary to mine the potential value of data to the benefit of people and their lives. However, the variety, volume, heterogeneity, and real-time nature of data obtained from smart cities pose considerable challenges. In this paper, we propose a semantic framework that integrates the IoT with machine learning for smart cities.
The proposed framework retrieves and models urban data for certain kinds of IoT applications based on semantic and machine-learning technologies. Moreover, we propose two case studies: pollution detection from vehicles and traffic pattern detection. The experimental results show that our system is scalable and capable of accommodating a large number of urban regions with different types of IoT applications.
RELATED WORK
Semantic IoT
To the best of our knowledge, our framework is the first involving semantics integrated with machine learning for IoT data of smart cities. The major task of the IoT is to represent the “things” by standard schemas. The W3C have developed an ontology representing sensors and data, providing metadata for spatial, temporal, and other objects. However, their work mainly focuses on defining a standard ontology for annotation of the IoT.
Smart City
Urban computing is a process of acquisition, integration, and analysis of a large amount of heterogeneous data generated by diverse sources in urban spaces, such as sensors, devices, vehicles, buildings, and humans, with the aim of addressing the major issues cities face (e.g., air pollution, increased energy consumption, and traffic congestion). According to, there are three main challenges associated with urban computing: urban sensing and data acquisition, computing with heterogeneous data, and hybrid systems blending the physical and virtual worlds.
APPROACH
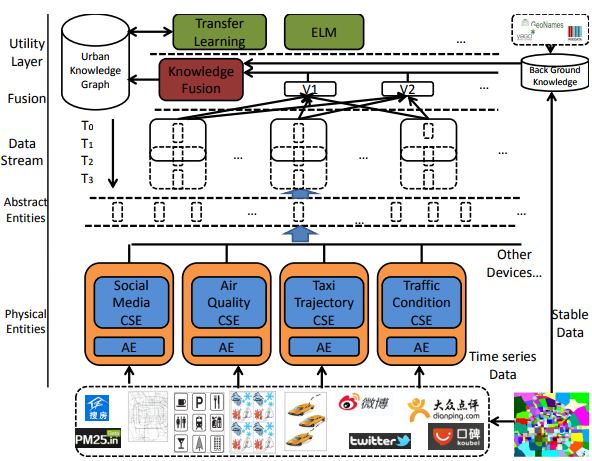
Figure 1. Semantic framework of IoT integrated with machine learning for smart city applications
We firstly divide the smart city into blocks according to the road networks. The different colors in the rectangle in the lower right corner of Figure 1 represent different blocks. For each block, we obtain amounts of stable (timeindependent) data from OpenStreetMap and the APIs of Google and Baidu, including POIs, the terrain, and road networks.
We also map the locations of blocks with entities from Yago2, Geoname, and WikiData to enrich our knowledge of a smart city. For instance, we may obtain a POI category “coffee shop” for “Starbucks” in a block. We can enhance the semantic meanings by matching the entities with the external knowledge bases.
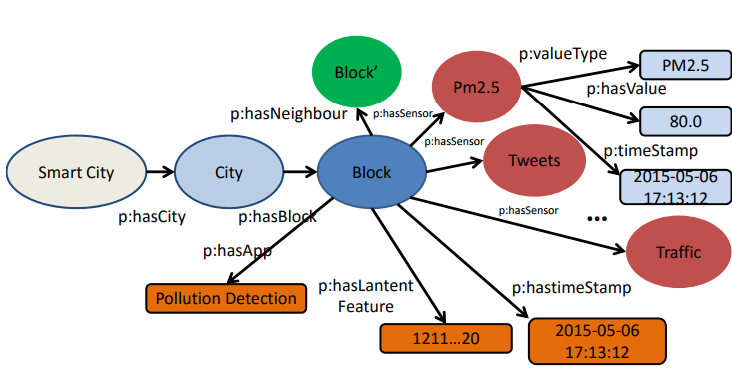
Figure 2. Simple concept model of urban knowledge graph
Figure 2 shows a simple concept model of an urban knowledge graph (the size of the figure is limited to enable more resources of a block to be shown). The model captures both types of resources for each block (PM2.5, AQI, traffic, terrain, weather, POIs) and the latent features (represented by a vector and a timestamp) through knowledge fusion, where “p” is the namespace of the properties. Each sensor has three properties: type, value, and time.
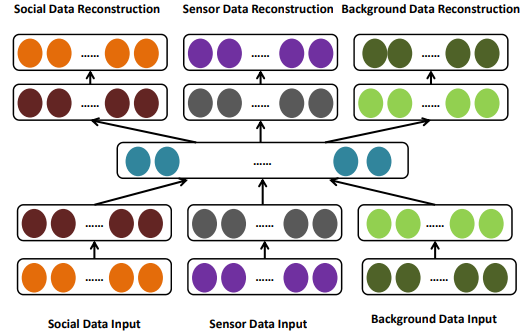
Figure 4. Urban knowledge fusion of learning latent representation
Sensor data is composed of values recorded by physical sensors such as the flow of taxis and buses, traffic congestion index, real estate, air quality, meteorological elements, and so on. The texts in social data are converted to vectors via a word-embedding procedure from GloVe. We adopt the deep autoencoder to capture the “middle-level” feature representation from these data. As depicted in Figure 4, the deep auto-encoder effectively learns (1) a more effective single modality representation with the help of other modalities and (2) shared representations by capturing the correlations across multiple modalities.
EXPERIMENTS
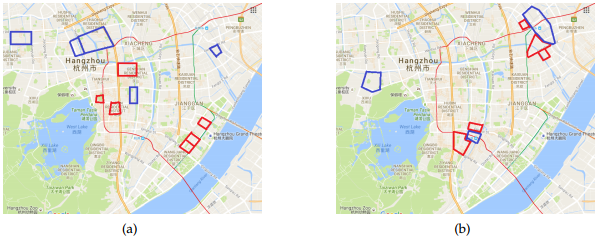
Figure 5. Traffic pattern analysis in Hangzhou
(a) Traffic pattern at 9:00; (b) Traffic pattern at 20:00.
We used our framework to mine the traffic patterns in Hangzhou. As Figure 5 shows, we identified interesting blocks that may indicate the potential traffic patterns in Hangzhou at 9:00 and 20:00. The areas outlined in red indicate blocks with considerable traffic inflow, whereas the areas outlined in blue indicate outflows. Actually, the red outlines in the image on the left recorded at 9:00 are located in the CBD according to the urban knowledge graph.
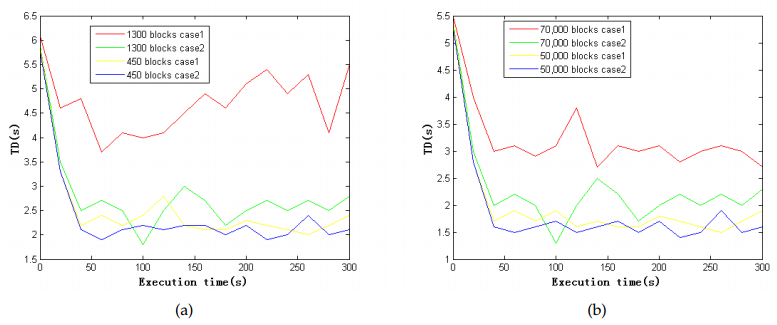
Figure 6. Processing time total delay(TD) with increased number of blocks
(a) TD with blocks in single node; (b) TD with blocks in cluster.
Figure 6 shows the processing time for a single node and for a cluster with different blocks. Case 1 refers to the case study involving pollution detection from vehicles, whereas Case 2 refers to the case study involving traffic pattern analysis. The number of blocks is varied from 450 to 1300. We performed the cluster experiment by duplicating the blocks using 50,000 to 70,000 nodes.
CONCLUSIONS
In this study, we proposed a semantic framework to integrate the IoT with machine-learning techniques from the perspective of a smart city. We discussed two case studies based on the implementation of our framework and obtained interesting results. In addition, we tested our proposed approach for scalability. The results showed that our approach is applicable in practice and that it is highly efficient. There are some limitations to this study, which should be addressed in future work. One major limitation lies in the partially missing data from some blocks and the limited availability of open data. For example, some data streams exist that do not have records when malfunction of sensors occur (a missing data stream in a time interval).
We would like to mine the data of blocks more deeply in the future to estimate the missing data. The adaptability of this approach to real-world circumstances will also be considered in our future work. First, some visual analytics functions will be added to our ongoing demonstration system. Through presenting similar historical circumstances or forecasting results according to different features, the system will be able to provide more information for flexible decision-making. We are also investigating a new model that utilizes data from similar historical circumstances through understanding the underlying semantics of the data. We plan to apply our approach to additional applications. Moreover, we aim to study the distribution of our framework to enable it to process very large amounts of data.
Source: Zhejiang University
Authors: Ningyu Zhang | Huajun Chen | Xi Chen | Jiaoyan Chen
>> IoT based Real-Time Projects for B.E/B.Tech Students
>> 200+ IoT Led Projects for Engineering Students
>> IoT Environmental Monitoring System for Smart Cities Projects for Final Year Students