ABSTRACT
Nowadays, Internet-of-Things (IoT) devices generate data at high speed and large volume. Often the data require real-time processing to support high system responsiveness which can be supported by localised Cloud and/or Fog computing paradigms. However, there are considerably large deployments of IoT such as sensor networks in remote areas where Internet connectivity is sparse, challenging the localised Cloud and/or Fog computing paradigms. With the advent of the Raspberry Pi, a credit card-sized single board computer, there is a great opportunity to construct low-cost, low-power portable cloud to support real-time data processing next to IoT deployments. In this paper, we extend our previous work on constructing Raspberry Pi Cloud to study its feasibility for real-time big data analytics under realistic application-level work load in both native and virtualised environments.
We have extensively tested the performance of a single node Raspberry Pi 2 Model B with httperf and a cluster of 12 nodes with Apache Spark and HDFS (Hadoop Distributed File System). Our results have demonstrated that our portable cloud is useful for supporting real-time big data analytics. On the other hand, our results have also unveiled that overhead for CPU-bound workload in virtualised environment is surprisingly high, at 67.2%. We have found that, for big data applications, the virtualisation overhead is fractional for small jobs but becomes more significant for large jobs, up to 28.6%.
RELATED WORK
Since its launch in 2012, the Raspberry Pi has quickly become one of the best-selling computers and has stimulated various interesting projects across both industry and academia that fully exploit the low cost low power full feature computer. As of 29 February 2016, the total number of units sold worldwide has passed 8 million.
Iridis-pi and Glasgow Raspberry Pi Cloud are among the first to use a large collection of Raspberry Pi boards to construct clusters. Despite their similarity in hardware construction, their nature is distinctively different. Iridis-pi is an educational platform that can be used to inspire and enable students to understand and apply high-performance computing and data handling to tackle complex engineering and scientific challenges. On the contrary, the Glasgow Raspberry Pi cloud is an educational and research platform which emphasises development and understanding virtualisation and Cloud Computing technologies. Other similar Raspberry Pi clusters include.
BACKGROUND
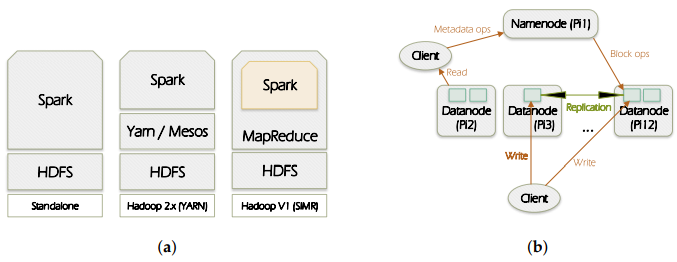
Figure 1. Spark and HDFS (Hadoop Distributed File System) overview
(a) Spark deployment; (b) HDFS architecture.
Figure 1a illustrates the ways in which Spark can be built and deployed upon Hadoop components. There are: (1) Standalone mode: where Spark interacts with HDFS directly but MapReduce could collaborate with it in the same level to run jobs in cluster; (2) Hadoop Yarn: Spark just runs over Yarn which is a Hadoop distributed container manager; (3) Spark in MapReduce (SIMR): in this case Spark can run Spark jobs in addition to the standalone deployment.
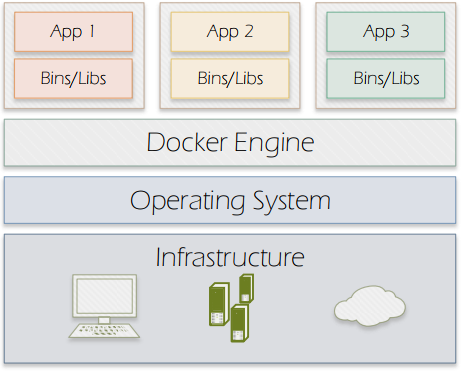
Figure 2. Docker containers
Docker (https://www.docker.com/what-docker) allows applications packaging with all their dependencies into software containers. Different from the Virtual Machine design which requires an entire operating system to run the applications on, Docker enables sharing the system kernel between containers by using the resource isolation features available on Linux environment such as cgroups and kernel namespaces. Figure 2 illustrates Docker’s approach.
EXPERIMENT SETUP
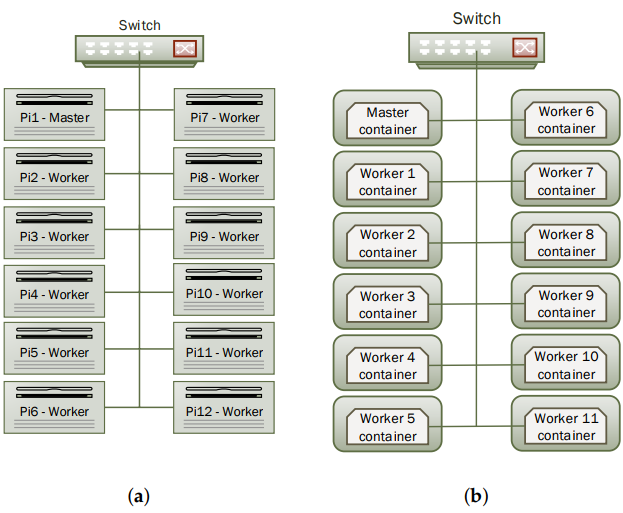
Figure 3. Cluster Layout
(a) Native set-up; (b) Virtualised set-up.
For Spark, each worker was allocating 768MB RAM and all 4 CPU cores. For HDFS, we set the number of replica to 11 so that data are replicated on each worker node. This set-up was not only considered for high availability but also to avoid high network traffic between nodes as we predict that Raspberry Pi has a hardware limitation on the network interface speed. Figure 3a shows the cluster design.
In the second phase of the experiment, we installed Docker and created a Docker container on each node of the cluster. Docker container hosts both Spark 1.4.0 and Hadoop 2.6.4 with the same setup as in the native environment. So the container is considered as a Virtual Machine running on the Raspberry Pi. We have established a network connection between the 12 containers and have made them able to communicate between each other. Figure 3b illustrates this set-up.
EXPERIMENT RESULTS
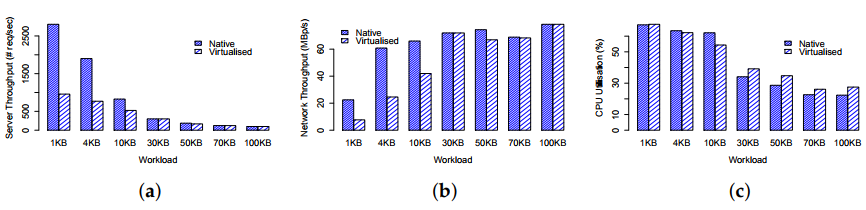
Figure 4. Single server performance
(a) Server throughput; (b) Network throughput; (c) CPU utilisation.
Our test results for single node performance are shown in Figure 4. We first examine the results for native environment. Obviously, Figure 4a shows that the average number of network requests served by the server decreases from 2809 req/s to 98 req/s for 1KB and 100KB workloads respectively. In the meantime, their corresponding network throughput, as shown in Figure 4b and CPU utilisation, as shown in Figure 4c exhibit monotonically increasing and decreasing patterns respectively, but with flatter tails.
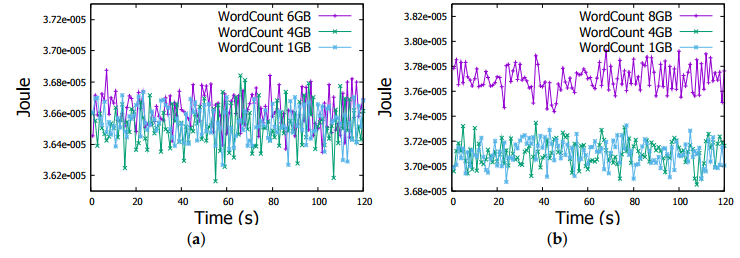
Figure 7. Energy measurement in a Raspberry Pi Worker node in WordCount job
(a) WordCount Job (1-4-6 GB files); (b) WordCount Job (1-4-8 GB files).
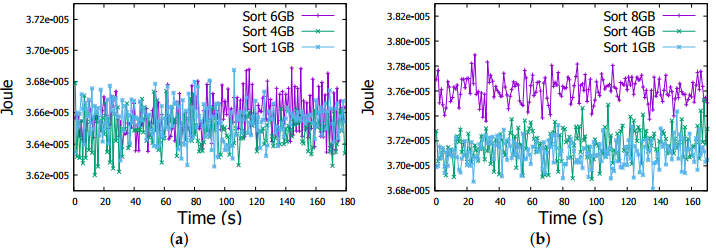
Figure 8. Energy measurement in a Raspberry Pi Worker node in Sort job
(a) Sort job (1-4-6 GB files); (b) Sort job (1-4-8 GB files).
Regarding the energy consumption, through Figures 7a and 8a we can obviously observe that actual energy consumption depends on the job sizes. It is slightly higher for 6GB files than for 1GB and 4GB files in both Word Count and Sort jobs. To confirm this observation, we run Word Count and Sort on file of 8GB, even with some task failures on some Raspberry Pis, we noticed the behaviour more clearly as shown in Figures 7b and 8b. Therefore, workload affects the energy consumption, the more intensive the workload is, the more important is the energy consumption by the Raspberry Pi device.
CONCLUSIONS
In this paper, we have designed and presented a set of extensive experiments on a Raspberry Pi cloud using Apache Spark and HDFS. We have evaluated their performance through CPU and memory usage, Network I/O, and energy consumption. In addition, we have investigated the virtualisation impact introduced by Docker, a container-based solution that relies on resources isolation features available on Linux kernel. Unfortunately, it has not been possible to use Virtual Machines as a virtualisation layer because this technology is not yet supported in the current releases on Raspberry Pi.
Our results have shown that the virtualisation effect becomes more clear and distinguishable with high workloads, e.g., when operating on a big amount of data. In a virtualised environment, CPU and memory consumption becomes higher, network throughput decreases, and burstiness occurs less often and less intensively. Furthermore, it has been proven that energy level consumed by the Raspberry Pi arises with the high workload and it is additionally affected by the virtualisation layer where it becomes more important.
As a future work, we are interested in attenuating the virtualisation overhead by investigating a novel traffic management scheme that will take into consideration both network latency and throughput metrics. This scheme will mitigate network queues and congestion at the levels of virtual appliances deployed in the virtualised environment. More precisely, it will rely on three keystones; (1) controlling end-hosts packets rate; (2) virtual machines and network functions placement; and (3) fine-grained load-balancing mechanism. We believe this will improve the network and applications performance but it will not have a significant impact on the energy consumption.
Source: Liverpool John Moores University
Authors: Wajdi Hajji | Fung Po Tso
>> IoT based Big Data and Cloud Computing Projects for B.E/B.Tech Students
>> IoT based Real-Time Projects for B.E/B.Tech Students
>> 200+ IoT Led Projects for Engineering Students
>> IoT Software Projects for Students