ABSTRACT:
One of the main factors that limit the accuracy of facial analysis systems is hand occlusion. As the face becomes occluded, facial features are either lost, corrupted or erroneously detected. Hand over-face occlusions are considered not only very common but also very challenging to handle.
Moreover, there is empirical evidence that some of these hand-over-face gestures serve as cues for recognition of cognitive mental states. In this paper, we detect hand-over-face occlusions and classify hand-over-face gesture descriptors in videos of natural expressions using multi-modal fusion of different state-of-the-art spatial and spatio emporal features.
We show experimentally that we can successfully detect face occlusions with an accuracy of 83%. We also demonstrate that we can classify gesture descriptors (hand shape , hand action and facial region occluded ) significantly higher than a na ̈ıve baseline. To our knowledge, this work is the first attempt to automatically detect and classify hand-over-face gestures in natural expressions.
CODING OF HAND-OVER-FACE GESTURES
Serving as a first step in automatic classification, we coded hand-over-face gestures using a set of descriptors. In this section, we describe the choice of the dataset, the coding schema, the labelling, annotation assessment and how we generate the ground truth labels that are used in our machine learning experiments.
Dataset:
The first challenge was to find a corpus of videos of natural expressions. Since most of the work on affect analysis focuses on the face, most of the publicly available natural datasets also focus on faces with limited or no occlusion. Since we are interested in the temporal aspect of the hand gesture as well, still photograph corpora did not satisfy our criteria.
Labelling:
In order to proceed to automatic detection, we needed to code the hand-over-face occlusions present in the dataset. The goal was to code hand gestures in terms of certain descriptors that can describe the gesture. Inspired by the coding schema provided by Mahmoud et al., we coded the gestures in terms of hand shape, hand action and facial region occluded.
- Hand Action
- Hand Shape
- Facial Region Occluded
Coding Assessment & Refinement:
To assess the coding schema and gain confidence in the labels obtained, we calculated inter-rater agreement between the two expert annotators using time-slice Krippendorff’s alpha, which is widely used for this type of coding assessment because of its independence of the number of assessors and its robustness against imperfect data. We got a Krippendorff’s alpha coefficient of 0.92 for hand action, 0.67 for hand shape and an average alpha coefficient of 0.56 for facial region occluded (forehead 0.69, eye(s) 0.27, Nose 0.45, cheeks 0.65, lips 0.73, chin 0.83, hair/ear 0.25).

Sample Frames From Videos In The Dataset Cam3d Showing Examples Of Face Touches Present In The Dataset .
FEATURE EXTRACTION
The first building block of our approach is feature extraction. We chose features that can effectively represent hand gesture descriptors that we want to detect. Therefore, we extract spatial features, namely: Histograms of Oriented Gradients (HOG) and facial landmark alignment likelihood. Moreover, having the detection of hand action in mind, we also extract Space Time Interest Points (STIP) that combine spatial and temporal information.
Space Time Features:
Local space-time features have become popular motion descriptors for action recognition. Recently, they have been used by Song et al. to encode facial and body microexpressions for emotion detection. They were particularly successful in learning the emotion valence dimension as they are sensitive to global motion in the video. Our methodology for space time interest points feature extraction and representation is based on the approach proposed by Song et al.
Facial Landmark Detection – Likelihood:
Facial landmark detection plays a large role in face analysis systems. In our case it is important to know where the face is in order to compute HOG appearance features around the facial region and to remove irrelevant STIP features.
We employ a Constrained Local Neural Field (CLNF) facial landmark detector and tracker to allow us to analyse the facial region for hand over face gestures. CLNF is an instance of a Constrained Local Model (CLM), that uses more advanced patch experts and optimisation function. We use the publicly available CLNF implementation.

An Example of Patch Expert Responses in Presence of Occlusion. Green Shows High Likelihood Values, While Red Means Low Likelihoods.
HOG:
Histograms of Oriented Gradients (HOG) are a popular feature for describing appearance that has been success fully used for pedestrian detection , and facial landmark detection amongst others.
HOG descriptor counts the number of oriented gradient occurrences in a dense grid of uniformly spaced cells. These occurrences are represented as a histogram for each cell normalised in a larger block area. HOG features capture both appearance and shape information making them suitable for a number of computer vision tasks
EXPERIMENTAL EVALUATION
For our classification tasks, we used the labelled subset of Cam3D described in Section 3.1 to evaluate our approach. It has a total of 365 videos of ∼2190 seconds, which contains ∼65700 frames (∼6570 data samples – one data sample per processing window w= 10).
Methodology:
As a pre-processing step, we performed face alignment on all of our videos. Face detection was done using Zhu and Ramanan’s face detector followed by refinement and tracking using CLNF landmark detector. After landmark detection, the face was normalised using a similarity transform to account for scaling and in-plane rotation. This led to a 160 × 120 pixel image. The output of the facial landmark detection stage was passed to the three feature extraction sub-systems.
Hand Occlusion Detection:
The first task in our experiments was hand-over-face occlusion detection. The face was considered to be occluded if one or many facial regions are labelled as occluded. For this task, we used a binary classifier to detect if the face is occluded or not. We trained a linear SVM classifier using single modalities and feature-level fusion.
The classification results (accuracy and F1 score) of uni-modal features and multi-modal fusion. We found that the best performance is obtained from the multi-modal linear classifier (Accuracy 0.83, F1 score 0.83), which is higher than a na ̈ıve majority vote classifier (Accuracy 0.56, F1 score 0.69) or chance (Accuracy 0.5).
Classification of Hand-over-Face gesture descriptors:
After occlusion detection, the second task was to classify hand-over-face gesture descriptors (hand shape, hand action and facial region occluded). We treated each descriptor as a separate classification task. Hand shape and facial region occluded classifications were performed per window w, while hand action classification was done per video.
Discussion:
Figure 5 summarises our classification results for hand detection and classification obtained for the six classification tasks. The results display mostly binary classifiers except for hand shape where we employed a 4 class classifier, hence the lower classification values. Our multi-modal fusion approach showed a statistically significant improvement over a naive classifier for all of our classification experiments.
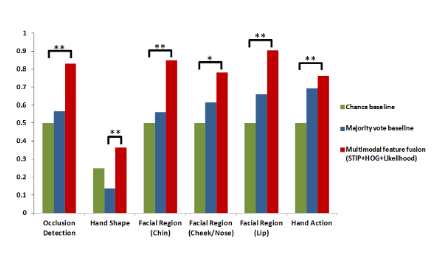
Figure 5: Classification Results Summary for All the Classification Tasks.
CONCLUSION AND FUTURE WORK
In this paper, we presented the first automatic approach to tackle the challenging problem of detection and classification of hand-over-face gestures. We treat the problem as two tasks: hand occlusion detection, then classification of hand gesture cues, namely-hand shape, hand action and facial region occluded.
We extract a set of spatial and spatio-temporal features (Histograms of Oriented Gradients (HOG), facial landmark detection likelihood, and space-time interest points (STIP) features). We use feature-specific dimensionality reduction techniques and aggregation over a window of frames to obtain a compact representation of our features.
Using a muti-modal classifier of the three features, we can detect hand-over-face occlusions and classify hand shape, hand action and facial region occluded significantly better than the majority vote and chance baselines. We also demonstrate that mutli-modal fusion of the features proved to outperform single modality classification results. We believe that adding more temporal features and improving the segmentation of the videos would improve the hand action detection results but we are leaving this to future work.
Future work also includes testing our multimodal features using more complex classifiers that incorporate temporal features. The coding schema can also be improved to include more hand articulations.
Source: University of Cambridge
Authors: Marwa Mahmoud | Tadas Baltrušaitis | Peter Robinson