ABSTRACT:
Identity-based proxy re-encryption schemes have been proposed to shift the burden of managing numerous files from the owner to a proxy server. Nevertheless, the existing solutions suffer from several drawbacks. First, the access permission is determined by the central authority, which makes the scheme impractical. Second,they are insecure against collusion attacks.
Finally, only queries from the same domain (intra-domain) are considered. We note that one of the main applications of identity-based proxy re-encryption schemes is in the cloud computing scenario. Nevertheless, in this scenario, users in different domains can share files with each other. Therefore, the existing solutions do not actually solve the motivating scenario, when the scheme is applicable for cloud computing.
Hence, it remains an interesting and challenging research problem to design an identity-based data storage scheme which is secure against collusion attacks and supports intra-domain and inter-domain queries. In this paper, we propose an identity-based data storage scheme where both queries from the intra-domain and inter-domain are considered and collusion attacks can be resisted. Furthermore,the access permission can be determined by the owner independently.
PRELIMINARIES
In the rest of this paper, by sR←S, we denotes is selected from S at random. If S is a finite set, by sR←S, we denotes is selected uniformly from S. By F(x)→y, we denote y is obtained by running the algorithm F on input x. A function E:Z→R is negligible if, for all z∈Z, there exists an integer k∈Z such that E(x)≤1xz whenx > k.
Identity-based Data Storage:
There are four entities in an identity-based data storage scheme: the private key generator (PKG), the data owner, the proxy server (PS) and the requester. The PKG validates the users’ identities and issues secret keys to them.
The data owner encrypts his files and outsources them to the proxy server. He validates the requesters and issues access permissions to the proxy sever. The proxy server stores the ciphertexts and can transfer them to ciphertexts for the requester when he obtains corresponding re-encryption keys from the owner.
Security Model:
The following game is used to formalize the security model of identity-based data storage scheme supporting intra-domain and inter-domain queries.This model is derived from the selective-identity secure IBE scheme.
IDENTITY-BASED DATA STORAGE SCHEME IN CLOUD COMPUTING
In this section, we propose an identity-based data storage scheme supporting intra-domain and inter-domain queries and prove its security. In our scheme, the access permission can be determined by the data owner independently without the need of the PKG. Especially, the access permission is bound to the requested ciphertext. Furthermore, our scheme is secure against the collusion attacks.
PERFORMANCE EVALUATION
The efficiency of pairing-based schemes is related to the selected elliptic curve. Literatures suggested that how to select elliptic curves for efficient cryptographic systems. In order to select a secure elliptic curve, two important factors must be considered: the group size l of the elliptic curve and the embedding degreed.
Benchmark Time:
The running time of different operations on the bilinear group is obtained on a DELL E630 with Intel(R) Core TM2 Duo CPU ( T8100@2.10GHz) and 2GB RAM running Ubuntu 9.10. The running time is calculated by computing the average of running the operation 10 times with random inputs using the text code from the PBC library.
Implementations of Our Scheme:
We implement our scheme on Type A curve: y2= x3+x, where G1=G2,the orderpis 160 bits, the embedding degree d= 2 and the group size l is 512 bits. Compared with the curves with d >2, the expensive paring operation is fastest on Type A curve.
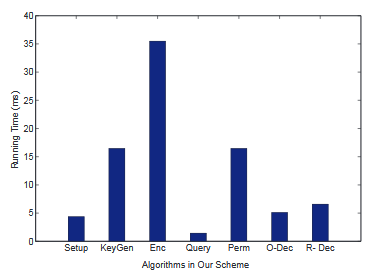
Comparison of The Running Time Consumed by the Algorithms : Setup, Key-Gen, Encryption, Query, Permission, Owner Decryption and Requester Decryption.
CONCLUSION
Cloud computing is a distributed system where users in different domains can share data among each other. Identity-based proxy re-encryption schemes have been proposed to outsource sensitive data from the owner to an external party.
Nevertheless, they cannot be employed in cloud computing. For example, they can only support the intra-domain query and the access key is computed with the help of the private key generator (PKG).
Additionally, the proxy server must be trusted. In this paper, we proposed an identity-based data storage scheme which is suitable to the cloud computing scenario as it supports both intra-domain and inter-domain queries.
In our scheme, the access key is bound to not only the requester’s identity but also the requested ciphertext, and can be computed by the owner independently without the help of the PKG. For one query, the requester can only access one file of the owner, instead of all files. Furthermore, our scheme is secure against the collusion attacks. We proved the security of the proposed scheme in the selective-identity model.
Source: University of Wollongong
Authors: Jinguang Han | Willy Susilo | Yi Mu