ABSTRACT
With the development of satellite load technology and very large scale integrated (VLSI) circuit technology, onboard real-time synthetic aperture radar (SAR) imaging systems have become a solution for allowing rapid response to disasters. A key goal of the onboard SAR imaging system design is to achieve high real-time processing performance with severe size, weight, and power consumption constraints.
In this paper, we analyze the computational burden of the commonly used chirp scaling (CS) SAR imaging algorithm. To reduce the system hardware cost, we propose a partial fixed-point processing scheme. The fast Fourier transform (FFT), which is the most computation-sensitive operation in the CS algorithm, is processed with fixed-point, while other operations are processed with single precision floating-point.
With the proposed fixed-point processing error propagation model, the fixed-point processing word length is determined. The fidelity and accuracy relative to conventional ground-based software processors is verified by evaluating both the point target imaging quality and the actual scene imaging quality. As a proof of concept, a field- programmable gate array—application-specific integrated circuit (FPGA-ASIC) hybrid heterogeneous parallel accelerating architecture is designed and realized.
The customized fixed-point FFT is implemented using the 130 nm complementary metal oxide semiconductor (CMOS) technology as a co-processor of the Xilinx xc6vlx760t FPGA. A single processing board requires 12 s and consumes 21 W to focus a 50-km swath width, 5-m resolution stripmap SAR raw data with a granularity of 16,384 × 16,384.
PARTIAL FIXED-POINT IMAGING SCHEME
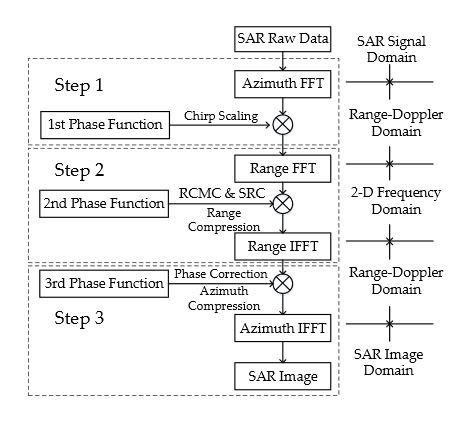
Figure 1. Flowchart of the CS algorithm
The flowchart of the CS algorithm is illustrated in Figure 1. First, the SAR raw data are transferred to the Range-Doppler domain via a FFT in the azimuth direction. Second, the data are multiplied by the 1st phase function to achieve the chirp scaling, which makes all the range migration curves the same.
FIXED-POINT IMAGING QUALITY EVALUATION
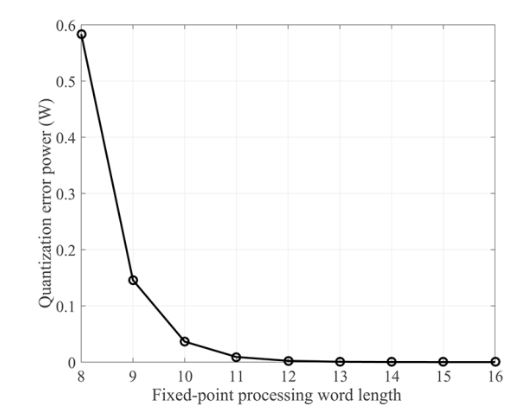
Figure 3. Quantization error power for different fixed-point processing word lengths
Figure 3 shows the quantization error power under different processing word lengths according to (11). As the word length increases from 8 to 11, the quantization error power gradually decreases. As the word length increases from 12 to 16, the quantization error power remains essentially unchanged. Therefore, we can narrow the scope of the word length for verification. In the following subsections, we evaluated the imaging quality of both a point target and an actual scene for 12-to 16-bit word lengths.
FPGA-ASIC HYBRID HETEROGENEOUS PARALLEL ACCELERATING ARCHITECTURE
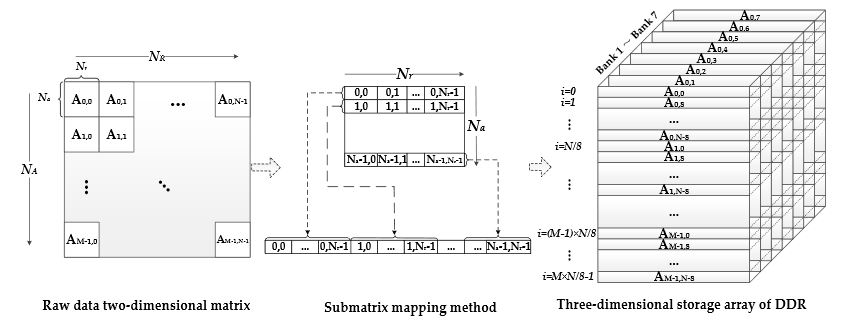
Figure 8. Submatrix Three-dimensional Mapping Method
The DDR-based matrix transpose is achieved by using the sub-matrix three-dimensional mapping method. In this way, the transpose operation can be performed simultaneously with data reading before the co-processors stage. The accessing of situ address data is the prerequisite of this method. The main procedure of this technology is shown in Figure 8, according to the following two steps.
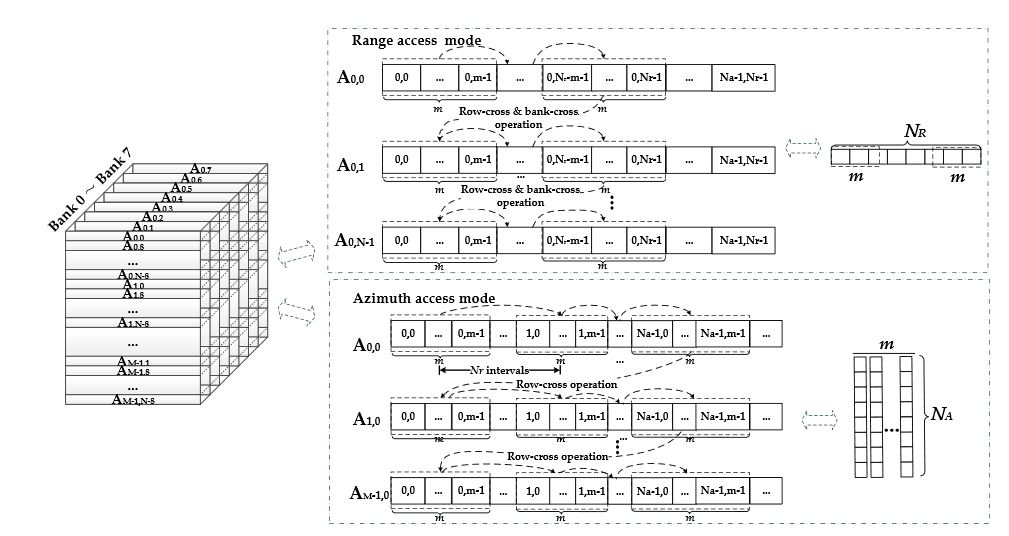
Figure 9. Range and azimuth access modes of the DDR SDRAM
Figure 9 shows the reading operation of the two modes from left to right. The writing operation has just the opposite procedure compared to the reading operation. Apart from the influence of the line-cross and bank-cross operations of each access mode, the maximum bandwidth utilization of the DDR also depends on whether the internal FPGA cache memory can match these two completely different access forms.
REALIZATION OF THE FPGA-ASIC ACCELERATING PLATFORM
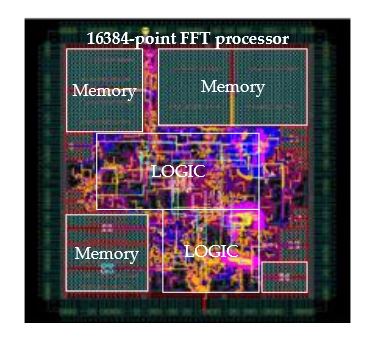
Figure 10. Layout of 16,384 point, 16-bit pipeline FFT processor
Figure 10 shows the primary layout of the chip. Table 8 summarizes the main specifications of the chip. The total power consumption is only 84.9 mW @ 125 MHz. The chip turns out to be an energy-efficient tool for implementing the FFT, which is the most computationally intensive operation in the CS processing flow.
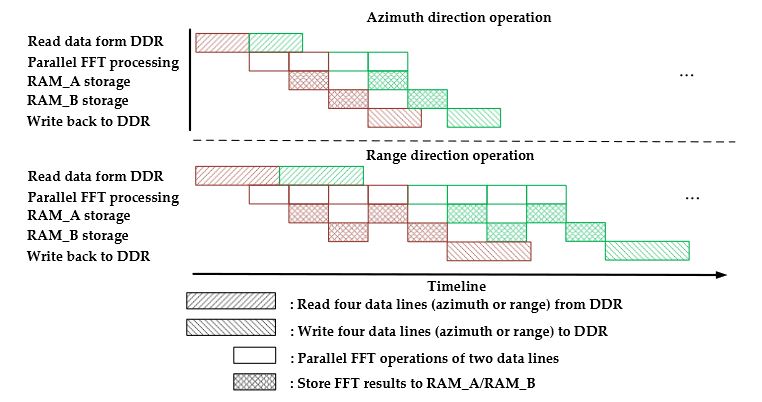
Figure 12. Parallel processing timeline of one round-robin assignment
In this stage, Steps 2 to 3 should be executed once more before moving on to Step 4. The parallel processing timelines of one round-robin assignment for both the range direction operation and the azimuth direction operation are described in Figure 12.
CONCLUSIONS
In this paper, to complete the on-board real-time SAR imaging processing procedure in harsh space conditions, a partial fixed-point imaging system using the FPGA-ASIC hybrid heterogeneous parallel accelerating technique is proposed. With a proposed fixed-point processing error propagation model, the fixed-point processing word length is determined. The imaging fidelity is verified via both a point target and an actual scene imaging quality evaluation.
Through a reasonable algorithm-to-system mapping, one Xilinx FPGA and two ASICs work together in parallel. The efficient architecture achieves high real-time performance with low power consumption. A single processing board requires 12 s and consumes 21 W to focus 50-km width, 5-m resolution stripmap SAR raw data with a granularity of 16,384 × 16,384.
Admittedly, the proposed design is a prototype verification of the spaceborne on-board real-time processor. Both the system scale and the power consumption meet the harsh constraints of on-orbit processing. With the development of anti-radiation reinforcement technology and system fault-tolerant technology, the proposed framework is undoubtedly expandable and feasible for potential spaceborne real-time SAR imaging processing.
Authors: Chen Yang | Bingyi Li | Liang Chen | Chunpeng Wei | Yizhuang Xie | He Chen | Wenyue Yu